平常工作生活中,不知你有没有遇到这种情况,有时访问网站异常的快,有时却要等待10多秒才会有响应, 这种情况下,我们一般不会太多的停留在网站,因为影响了用户体验。今天就分享记录下,我工作中遇到的 一个问题。
问题现象
第一次发现这个问题,应该是在很早之前,我本地用浏览器访问我们公司的业务网站,发现有时很快,有时达到8、9秒以上, 但是也没有太在意,以为是偶尔一次的。另外我用手机4G网络也测试访问了下,速度挺快的。
然而当站点可用性监控系统刚上线运营的时候,就经常收到报警的通知,因为设置了探测 超时时间,我设置的是5秒。当时觉得可能就这一个站点误报,我单独把这个站点的超时设置了10s,但过了几天后,报警还是会误报, 终于忍不住了。
这里要自我检讨下,发现问题时,我投机取巧的去掩盖问题,而没有去正视这个问题。这种态度是要不得的。不然问题会像滚雪球一样可怕!!!
现象总结:公司某个网站监控得到的响应时间,延迟大,非常不稳定, 导致站点可用性监控经常误报警
环境介绍分析及测试
环境介绍
这里我介绍下整体的大致环境,这几台业务主机上,每台主机都有一个nginx,用于处理虚拟主机。然后最上面有一个公网LB(负载均衡器)。 它负责接收外部的流量,终止ssl,均衡的分发请求到每个主机的nginx上。
还有一点需要介绍下,我们线上还有一个公网LB,也是转发流量到这几台主机nginx上。这俩LB的区别只是加载的域名ssl证书不一样,其它配置一摸一样(让我一直在纠结是LB配置的原因)。 最后就是监控系统是部署在容器集群里的(很大程度的迷惑了自己,我曾以为是容器网络出现了延时问题…)。
分析
当时想了以下几个点:
- 公网LB 配置错误
- 某台应用主机处理请求时间过长
- 监控系统部署所在集群的网络问题
- 应用主机系统参数有问题(最后追加上去的,我还真没想到这块)
测试
公网LB 配置错误
针对这个问题,检查了LB的的配置的超时时间,缓存等选项,都没有啥结果,后来想到了日志,在haproxy的日子里,经常看到这样的消息。下面是截取的其中一条记录:
Jun 15 16:45:29 18.19.1.12 haproxy[30952]: 139.1.2.3:61653 [15/Jun/2018:16:45:08.784] lbl-ckv7ynro~ lbl-ckv7ynro_default/lbb-izjpmxrh 327/15003/-1/-1/20331 503 213 - - sCNN 4/3/0/0/+3 0/0 "HEAD /sessions/auth?return_to=%2F HTTP/1.1"以前没咋看过haproxy 日志,nginx日志倒是都明白,这一看傻眼了。查查文档吧。下面是对每段的解释:
Jun 15 16:45:29 # 时间
18.19.1.12 # haproxy ip
haproxy[30952]: # 进程ID
139.1.2.3:61653 #client_ip+port
[15/Jun/2018:16:45:08.784] #通过haproxy接收到连接的确切日期时间
lbl-ckv7ynro~ #前端监听器name
lbl-ckv7ynro_default/lbb-izjpmxrh #管理与服务器连接的后端/ 命中的 真实server主机
327/15003/-1/-1/20331
#327 是在接收到第一个字节后等待来自客户端(不包括正文)的完整HTTP请求花费的总时间(毫秒)
#15003 是在各种队列中等待的总时间(毫秒)。如果连接在到达队列之前中止,则可以为“-1”。
#-1 是等待连接建立到最终服务器的总时间(以毫秒为单位),包括重试次数。 如果请求在建立连接之前被中止,它可以是“-1”。
#-1 是等待服务器发送完整HTTP响应的总时间(毫秒),不计算数据。 如果在接收到完整的响应之前请求被中止,它可以是“-1”。 它通常与服务器的请求处理时间相匹配,尽管它可能会被客户端发送到服务器的数据量所改变。 “GET”请求的大部分时间通常表示重载的服务器。
#20331 是请求在haproxy中保持活动的时间,这是在接收到的请求的第一个字节和发送的最后一个字节之间经过的总时间(以毫秒为单位)。 它涵盖所有可能的处理,除了握手(见Th)和空闲时间(参见Ti)
503 #http状态码
213 #是发送日志时发送到客户端的总字节数
- #是一个可选的“name = value”条目,指示客户端在请求中具有此cookie。 未设置 -表示
- #是一个可选的“name = value”条目,表示服务器已经返回了一个具有响应的cookie。
sCNN #http格式下,会话状态,结束时会话的条件:(timeout, error)
#s 在等待服务器发送或接收数据时,服务器端超时已过期
#C 代理正在等待CONNECTION在服务器上建立。 服务器最多可能已经注意到连接尝试。
#N client没有提供cookie。这通常是新的访客,第一次访问的情况,所以计算在日志中这个标志的出现次数,通常表示站点被频繁访问的有效趋势。
#N 服务器没有提供cookie,也没有插入任何cookie。
4/3/0/0/+3
#4 是会话记录时进程上的并发连接总数
#3 是会话记录时前端上的并发连接总数
#0 是会话记录时由后端处理的并发连接的总数
#0 是在会话记录时服务器上仍然处于活动状态的并发连接总数
#+3 是尝试连接到服务器时此会话遇到的连接重试次数
0/0 # 前一个数字0 是在服务器队列中之前处理的请求的总数,后一个数字0是是在服务器队列中之前处理的请求的总数
"HEAD /sessions/auth?return_to=%2F HTTP/1.1" #是完整的HTTP请求行,包括方法,请求和HTTP版本字符串。上面的日志分析中,有很多有价值的信息,值得关注的有 4/3/0/0/+3, sCNN. 但是当时我只关注了超时这一点,以为是网络原因导致的客户端连接后端服务器的超时,然后就继续排查了。这里其实差不多已经
说明了出问题的点:lb 和 后端服务器之间的故障(后话,我忽略了这一点)。
某台应用主机处理请求时间过长
针对这个的测试,我准备在夜间流量低峰时,暂时禁用掉其它的LB后端,只保留1台后端主机进行对外服务。很快的我发现这也行不通。问题依旧会出现。逐个的去替换,这一个测试没效果。
监控系统部署所在集群的网络问题
做这个测试时,我还请了外援。让别人在他们公司内部帮忙用ab 访问下。分别是外部联通、外部电信、Google云主机、VPC内部。 下面是ab针对域名访问的结果。 LB1: lb1.example.com LB2: lb2.example.com
LB1 的ab 测试结果:
联通测试:
Server Software: nginx
Server Hostname: lb1.example.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256
Document Path: /favicon_128.ico/
Document Length: 2406 bytes
Concurrency Level: 1
Time taken for tests: 17.629 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Non-2xx responses: 100
Total transferred: 276000 bytes
HTML transferred: 240600 bytes
Requests per second: 5.67 [#/sec] (mean)
Time per request: 176.291 [ms] (mean)
Time per request: 176.291 [ms] (mean, across all concurrent requests)
Transfer rate: 15.29 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 16 121 157.1 20 653
Processing: 8 55 104.7 11 633
Waiting: 8 53 99.1 11 633
Total: 26 176 188.5 36 668
Percentage of the requests served within a certain time (ms)
50% 36
66% 241
75% 245
80% 248
90% 452
95% 658
98% 663
99% 668
100% 668 (longest request)
电信测试:
Server Software: nginx
Server Hostname: lb1.example.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256
Document Path: /favicon_128.ico/
Document Length: 2406 bytes
Concurrency Level: 1
Time taken for tests: 69.515 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Non-2xx responses: 100
Total transferred: 276000 bytes
HTML transferred: 240600 bytes
Requests per second: 1.44 [#/sec] (mean)
Time per request: 695.151 [ms] (mean)
Time per request: 695.151 [ms] (mean, across all concurrent requests)
Transfer rate: 3.88 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 108 120 5.7 121 132
Processing: 40 575 1527.9 45 5049
Waiting: 40 575 1527.9 45 5049
Total: 148 695 1527.5 166 5175
Percentage of the requests served within a certain time (ms)
50% 166
66% 171
75% 173
80% 174
90% 5154
95% 5167
98% 5173
99% 5175
100% 5175 (longest request)
LB2 的ab 测试结果:
联通测试:
Server Software: nginx
Server Hostname: lb2.example.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256
Document Path: /favicon_128.ico/
Document Length: 2406 bytes
Concurrency Level: 1
Time taken for tests: 17.168 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Non-2xx responses: 100
Total transferred: 276000 bytes
HTML transferred: 240600 bytes
Requests per second: 5.82 [#/sec] (mean)
Time per request: 171.675 [ms] (mean)
Time per request: 171.675 [ms] (mean, across all concurrent requests)
Transfer rate: 15.70 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 16 139 161.6 20 840
Processing: 8 32 87.1 10 641
Waiting: 8 32 87.1 10 641
Total: 25 171 176.9 235 852
Percentage of the requests served within a certain time (ms)
50% 235
66% 241
75% 245
80% 248
90% 255
95% 655
98% 667
99% 852
100% 852 (longest request)
电信测试:
Server Software: nginx
Server Hostname: lb2.example.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256
Document Path: /favicon_128.ico/
Document Length: 2406 bytes
Concurrency Level: 1
Time taken for tests: 16.714 seconds
Complete requests: 100
Failed requests: 0
Write errors: 0
Non-2xx responses: 100
Total transferred: 276000 bytes
HTML transferred: 240600 bytes
Requests per second: 5.98 [#/sec] (mean)
Time per request: 167.144 [ms] (mean)
Time per request: 167.144 [ms] (mean, across all concurrent requests)
Transfer rate: 16.13 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 110 122 4.9 122 136
Processing: 40 45 5.8 45 100
Waiting: 40 45 5.8 45 99
Total: 150 167 8.8 166 225
Percentage of the requests served within a certain time (ms)
50% 166
66% 170
75% 171
80% 172
90% 175
95% 176
98% 183
99% 225
100% 225 (longest request)
VPC 内部测试(统一出口):
LB1 的测试结果:
Server Software: nginx
Server Hostname: lb1.example.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256
Document Path: /favicon_128.ico/
Document Length: 2406 bytes
Concurrency Level: 1
Time taken for tests: 513.333 seconds
Complete requests: 100
Failed requests: 1
(Connect: 0, Receive: 0, Length: 1, Exceptions: 0)
Non-2xx responses: 100
Total transferred: 273453 bytes
HTML transferred: 238302 bytes
Requests per second: 0.19 [#/sec] (mean)
Time per request: 5133.329 [ms] (mean)
Time per request: 5133.329 [ms] (mean, across all concurrent requests)
Transfer rate: 0.52 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 4 5 2.3 4 21
Processing: 4 5128 4147.8 5007 20006
Waiting: 4 5128 4147.8 5007 20006
Total: 9 5133 4147.6 5012 20011
LB2 的测试结果:
Server Software: nginx
Server Hostname: lb2.example.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256
Document Path: /favicon_128.ico/
Document Length: 2406 bytes
Concurrency Level: 1
Time taken for tests: 1.099 seconds
Complete requests: 100
Failed requests: 0
Non-2xx responses: 100
Total transferred: 276000 bytes
HTML transferred: 240600 bytes
Requests per second: 91.00 [#/sec] (mean)
Time per request: 10.990 [ms] (mean)
Time per request: 10.990 [ms] (mean, across all concurrent requests)
Transfer rate: 245.26 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 4 5 1.7 4 16
Processing: 4 6 2.4 5 22
Waiting: 4 6 2.4 5 22
Total: 8 11 2.9 10 26
Percentage of the requests served within a certain time (ms)
50% 10
66% 11
75% 11
80% 12
90% 14
95% 17
98% 24
99% 26
100% 26 (longest request)
google 的测试结果没有放上来,相比国内访问是慢了点。这里主要关注了在VPC内部测试时,LB1的结果很不理想。 但是LB2的结果又很正常。看到之前的环境介绍,再配合这个结果,又把我拉回了原来的思路上,即LB 和vpc内部网络有问题。头大…. 哦,忘记说了一件事,我也在nginx主机上和vpc 内部其它主机上通过修改请求header,直接访问内部IP请求资源,这里是没有问题的,响应特别快。这又能证明主机上服务运行良好。网络也可以排除。这。。。悲剧了。
应用主机系统参数有问题
后来请教别人,最后告诉我看看内核参数recycle。然后我又去网上查了下,看看有没有类似的问题,但是不好查啊,环境都不一样。但是最后查到一条关于nat环境下,
在应用服务器上设置内核参数时,启用了net.ipv4.tcp_tw_recycle 和 net.ipv4.tcp_tw_reuse. 按照这个思路
导致有些客户端连接服务器失败,根据这个我去看了下服务器的配置,果不其然,有这个参数的优化。
验证结果
在手动的执行下面这条命令后:
sysctl -w net.ipv4.tcp_tw_recycle继续在vpc网络内部测试,发现对该lb的ab测试全部都正常了。。。。。
真是应了那句话,差不多一切的问题不是网络问题就是配置问题。。
下面是修改前后的监控对比图:
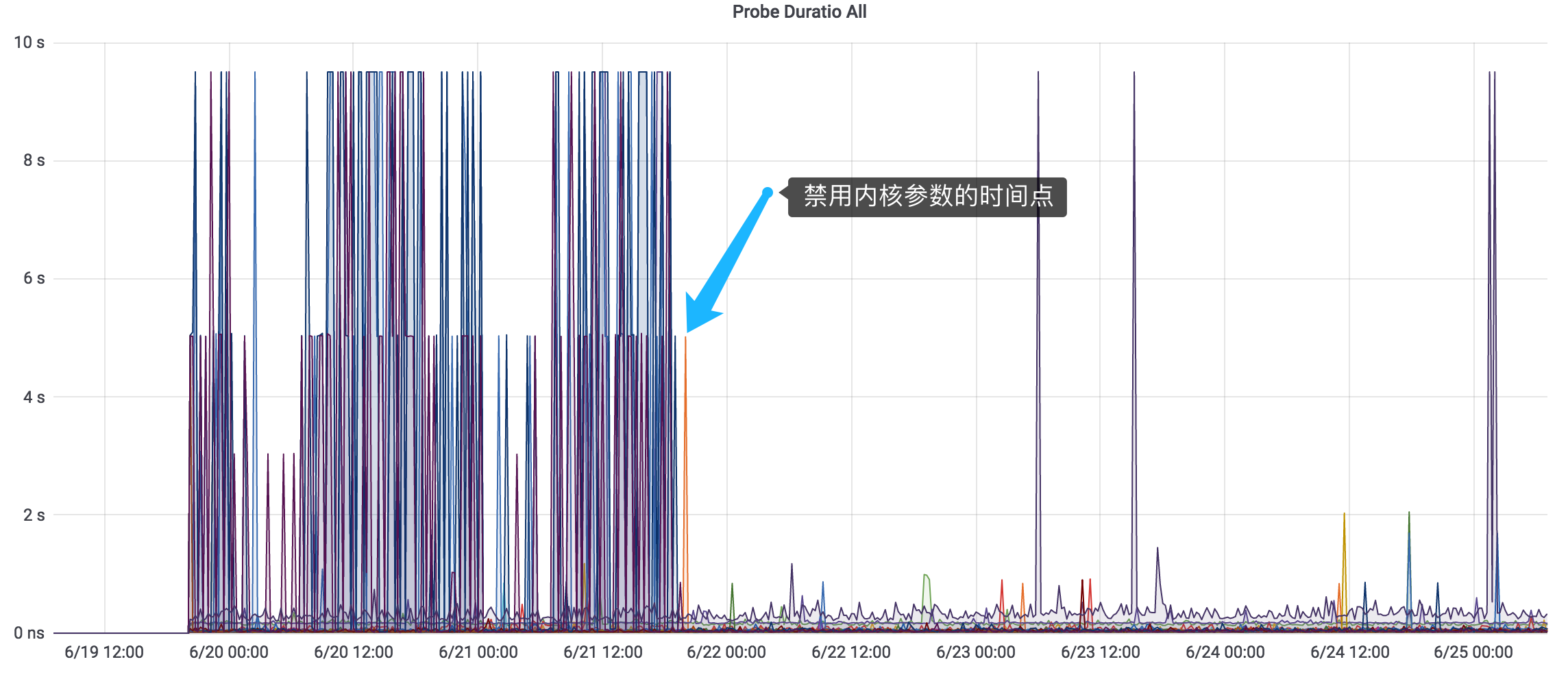
图1:URL监控响应时间图
分析根本原因
这里提出了2个问题,便于理解记忆全文。
- 为什么启用这个tcp recycle?
- 为什么启用tcp recycle之后,会阻塞部分用户的连接请求?
为什么启用这个tcp recycle?
这个是之前在部署应用主机系统时,修改优化了部分内核参数,当时想的是为了增大主机对tcp的连接性能,防止遇到并发用户的连接,导致tcp 连接不能快速释放,从而引发服务器 出现性能上的瓶颈(会导致服务器内存和CPU的暴增)。因为client 与server 建立链接传输完数据后,会断开链接,而服务器这边还会有2MSL的 time_wait 时间,超过这个时间之后,正常情况下,该socket才会被释放, 然后才可以接收其它client的请求。因为server 的端口是有固定范围的,不是说65535个全部都用来建立连接( 可参看系统内核配置:net.ipv4.ip_local_port_range)。
另外关于time_wait具体的可以参考tcp 的4次断开后的状态。 所以为了快速回收和重新使用,才开启了 tcp的reuse 和 recycle。但没想到这个会引起这么大的问题。 并且这个参数之前确实也在前公司用过。但没有发现这个类似的问题(也可能是当时的监控不到位,没有发现也不代表该问题不存在。)。 这里是官方内核文档对这俩参数的解释:
net.ipv4.tcp_tw_recycle:
Enable fast recycling TIME-WAIT sockets. Default value is 0. It should not be changed without advice/request of technical experts.
net.ipv4.tcp_tw_reuse:
Allow to reuse TIME-WAIT sockets for new connections when it is safe from protocol viewpoint. Default value is 0. It should not be changed without advice/request of technical experts.
而TIME-WAIT时间为2MSL的作用就是为了以确保属于未来连接的数据包不会被误认为是旧连接的延迟数据包。tcp_tw_reuse 可以在TIME_WAIT状态到期之前使用套接字,内核将尝试确保没有关于TCP序列号的冲突。
如果启用tcp_timestamps(默认是开启的,也就是PAWS,用于保护包装序列号),它将确保不会发生这些冲突。
为什么会阻塞客户端(Nat 环境)请求?
上面说了为什么启用它,现在在讨论下,为什么启用它后,会导致部分用户的链接,而不是全部? 看了一些文档及别人提到的解释:
当启用tcp_tw_recycle时,内核变得更具攻击性,并将对远程的client建立连接请求时使用的时间戳进行假设。它将跟踪具有TIME_WAIT状态连接的每个远程的client使用的最后时间戳, 并允许在时间戳正确增加时重新使用套接字。但是,如果主机使用的时间戳发生更改(即server 上记录time_wait中有A 客户端的上一个请求的时间戳是111112,现在又出现一了一个A 客户端的数据请求,并且序列号是111111.), 则SYN数据包将以静默的方式丢弃,并且连接将无法建立(将看到类似于“connect timeout”的错误)。
为什么我看不到关于connect timeout 的错误呢? 因为在这个环境下,client 相当于是最前面的LB,即haproxy,从这里也很好的解释了,为什么haproxy 的日志有很多连接重试的记录!
因为在NAT(网络地址转换) 环境下,有很多的client,流量进出都是通过一个公网IP出去的。但当多个NAT 网络环境下的用户同时或者短时间内去访问server 端的话,
因为对于server来说,此时我只知道有一个IP(client的公网IP)与我建立连接,
并且这里启用了tcp_tw_recycle,Server主机内核将认为有一部分连接请求的时间戳不是递增的,那么内核将判断该请求是无效的,就会丢失该请求。
To keep the same guarantees the TIME-WAIT state was providing, while reducing the expiration timer, when a connection enters the TIME-WAIT state, the latest timestamp is remembered in a dedicated structure containing various metrics for previous known destinations. Then, Linux will drop any segment from the remote host whose timestamp is not strictly bigger than the latest recorded timestamp, unless the TIME-WAIT state would have expired
总结
不要开启tcp_tw_recycle!!! .重要的话说三遍。
一定要有配置管理!可以方便在系统出问题时,检查对主机所做的历史记录。考虑问题不能光从
软件程序、网络上,还要加入对主机系统的分析。tcpdump、ss、还有log等。
另外,针对web 应用服务系统几个优化建议:
- 设置
net.ipv4.ip_local_port_range合理的范围(10000~63000) - 给LB设置更多的client IP。
- 配置LB 有多个外网IP。